
2010年頃から問題視されているものにsearch.msn.comからのアクセスがある。
UA(UserAgent)を見ると普通のブラウザで、検索用のロボットとはなっていない。
ちなみにbingの検索用のロボットはUAにbingbotが入っているのだが、当該アクセスにはない。
他の記事によるとrobot.txtも読まずにアクセスしてくるそうなので、かなり行儀が悪い。
アクセス頻度は高いものではなく30秒に1回くらいの割合でページを読みに来る。
ページを読みに来るというか、その時に見たログだと画像を持って行っている。
何故search.msn.comが嫌かというと、リダイレクトをちゃんと理解しないようで、ループに陥ってエラーが出る。
UAでの対策はしているのだが、通常のブラウザとしてアクセスしてくるので引っかからない。
ループの原因自体を直せば良いのだが、これがちょっと面倒だ。
スマートフォンからのアクセスではスマートフォン用のページを表示するようにしている。
しかしスマートフォンからでもPC用のページを見られるようにもしている。
ここに一つのループ要因があるのだが、通常のブラウザであれば上手く動作する。
所がサーチロボットの場合はこれをちゃんと解釈しないので、スマートフォンのページからPCページに行こうとするが、再びスマートフォンのページの方にアクセスしてループになる。
またWordpressはマルチサイト設定になっていて、これは仮想ディレクトリを使う。
従ってリダイレクトによってアクセスを可能にしているわけで、ここにも引っかかる。
正常なアクセスの場合は未だ良いのだが、例えばWordpressで実在しない画像をアクセスに来るとする。
aaaa.jpgとaaab.jpgがあったから、次はaaac.jpgみたいに。
しかし実際にはaaac.jpgは存在しないので、Wordpressは(大抵は)カレントディレクトリにリダイレクトするのだが、これを上手く理解出来ないようでループになる。
msn.comとapplebotを排除するのが良いのだが、IPアドレス範囲が広いのでそれも大変。
FQDNで排除しようとすると、毎回逆引きが起きるのでレスポンスが悪化する。
仕方がないので.htaccessの大幅改造を行った。
これでたぶん大丈夫かなと思うと、存在しないファイルやディレクトリへのアクセスを試みる様子が確認された。
これはエラーが返るのだが、ディレクトリに関しては(Webとして)公開はしていないが存在しているものがある。
search.msn.comとappleBotは不正アクセス並みのことをしてくる。
applebotは相当古い情報を元にしているのか?かなり以前に消したディレクトリへのアクセスを行ってくる。
iモードブラウザ用のフォーマット変換のcgiなどを狙ってくるって、一体いつの情報を元にしているんだか。
通常のブラウザからのアクセスなら404エラーが返るだけなのだが、msnやapplebotはブラウザ並みの解釈をしないので厄介だ。
search.msn.comはNotFoundのcgiファイルを何度も何度もアクセスしてくる。
HTTP404エラーを解釈しないのか?
狙ってくるのは1つのcgiファイルで、ログを見ると1週間ほど前からそのファイルだけを狙ってきている。
IPアドレスを変えながらアクセスを繰り返してくるのだが、割り当てアドレス分を全部切り替えてトライしてくるのだろうか??
IPアドレスを変えようが何をしようが、無いファイルは無いのだ。
例えば存在しないファイルにアクセスしてくると通常は404を返すわけだが、おかしなアクセス方法のされるapplebotに対しては500を返すことになる。
これはRewriteをBotが上手く解釈してくれないので、サーバエラーが起きるからだ。
これに関しては修正が結構面倒だった。
WordPressは仮想ディレクトリでアクセス出来るようになっているので、Rewriteが必要になる。
記事だけではなく画像にアクセスするのもディレクトリの制御をしている。
したがってRewriteを制限すると、Wordpress自体の機能が失われてしまう。
そもそもブラウザで正しく見えるように構成されているわけで、解釈の違うbot用には作られていない。
Googleは色々と文句を言って来るが、間違っている。
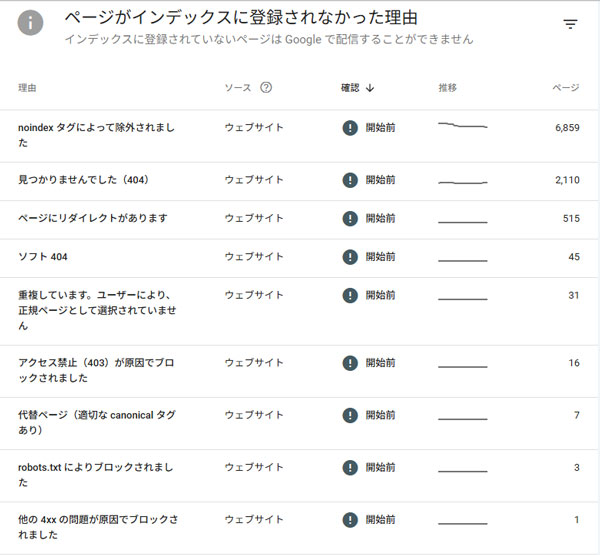
例えばnoindexタグによって制限されているページが6,859あるとなっているが、noindexタグなど存在していない。
404は消えてしまったページだし、リダイレクトはそういう構造なのだから仕方がない。

コメント